Clonando uma Voz usando RVC
Retrieval Based Conversion é uma tecnologia de inteligência artificial que te permite clonar ou transformar vozes, diferente de modificadores de voz antigos que alteram os aspectos da voz programaticamente, o RVC usa redes neurais profundas pra capturar o timbre, sotaque, e aplicar esses parâmetros a uma gravação de áudio diferente. O modelo analisa o áudio original, extrai a entonação, e cria um banco de dados de vetores, as características sonoras que correspondem ao áudio original, e depois realiza uma síntese pra reconstruir o áudio usando o timbre da voz alvo.
O RVC explodiu em popularidade nos ultimos anos por alguns motivos, o primeiro deles é a eficiência, o RVC requer poucos dados pra criar um modelo de voz decente. Com apenas 10 minutos de áudio limpo de uma pessoa, é possível treinar um modelo para imitá-la, o resultado é surpreendentemente natural e realista, e por ser uma tecnologia de código aberto, qualquer pessoa com um computador razoável pode baixar um projeto que implementa o software e criar seus próprios modelos.
Então é exatamente isso que vamos fazer hoje, eu vou demonstrar como construir um dataset para o treinamento e também implementação de um clone de voz usando o RVC.
REQUISITOS NECESSÁRIOS
Antes de iniciarmos o processo, vamos falar sobre requisitos. RVC é um processo intensivo de Deep Learning, e a eficiência do treinamento depende diretamente desses componentes:
- GPU (Preferencialmente NVIDIA): Embora o uso de uma GPU NVIDIA seja altamente recomendado devido à maturidade dos núcleos CUDA, ele não é estritamente obrigatório. É possível rodar o RVC em GPUs AMD ou Intel utilizando camadas de compatibilidade como ROCm ou DirectML, embora o desempenho e a estabilidade costumem ser superiores em hardware NVIDIA. Placas com pelo menos 8GB de VRAM são recomendadas para evitar gargalos no tamanho do lote (batch size).
- Dataset de Áudio: Você precisará de aproximadamente 10 minutos de áudio base. O segredo aqui não é a duração, mas a pureza: o áudio deve estar o mais “seco” possível (sem música de fundo, eco ou ruídos ambientais).
- Ferramentas de Versão e Runtime: Certifique-se de ter o Git e o Python instalados no sistema
- Sistema Operacional: Embora o fork suporte Windows, o uso de Linux é preferencial devido à gestão de memória e drivers. Caso você opte pelo Windows nativo, é obrigatório instalar o Visual Studio com as cargas de trabalho de “Desenvolvimento para desktop com C++”, o SDK do Windows 11 e o NVIDIA CUDA Toolkit. Ou você pode só usar o WSL (Windows Subsystem for Linux) (TODOS OS CAMINHOS LEVAM AO LINUX)
PREPARANDO O DATASET PRA GERAÇÃO DE ÁUDIO
A qualidade do modelo final é diretamente proporcional à pureza do dataset. Como o RVC captura nuances microscópicas do áudio, qualquer ruído de fundo, eco ou música será interpretado como parte do timbre da voz, gerando artefatos na conversão. Para este tutorial, eu usei de 9 minutos de uma leitura de “O Príncipe” (obrigado Cauã por nos emprestar sua voz).
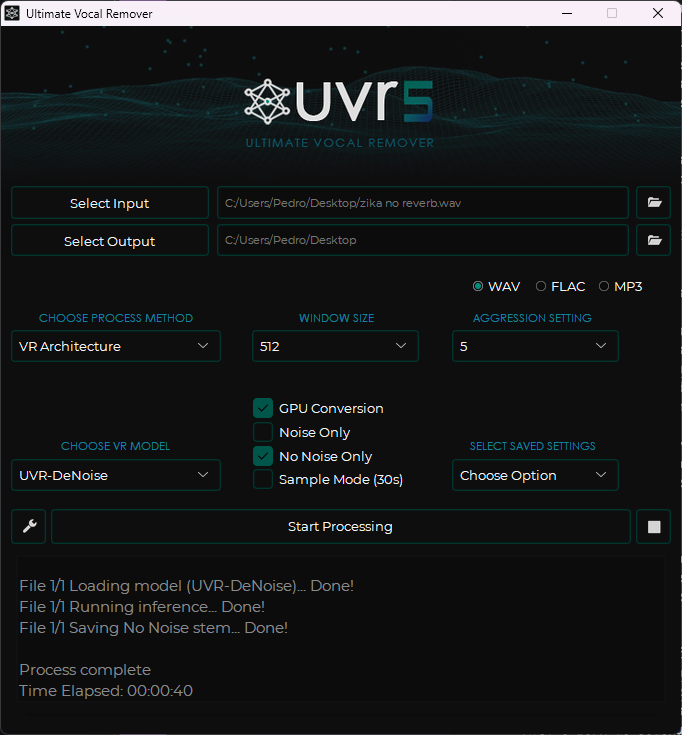
O primeiro passo crítico é o isolamento vocal via Ultimate Vocal Remover. Para o processamento, utilizaremos os modelos UVR-DeNoise (para remover ruídos de fundo) e UVR-DeEcho-DeReverb (para eliminar a acústica da sala). Certifique-se de salvar apenas as versões finais sem ruído e sem reverberação. Além disso, não esqueça de marcar a opção de utilização de GPU nas configurações do UVR para acelerar significativamente o processo de extração.
Após o isolamento, utilizamos o Audacity para um refinamento cirúrgico. O objetivo aqui é maximizar a densidade de dados úteis no dataset, removendo ruídos residuais que o UVR possa ter deixado passar.
Primeiro, aplicamos um Noise Gate (geralmente configurado em -40dB, dependendo do ganho da gravação) para garantir um silêncio absoluto entre as frases. Em seguida, utilizamos a função Truncate Silence para remover pausas longas e condensar o áudio.
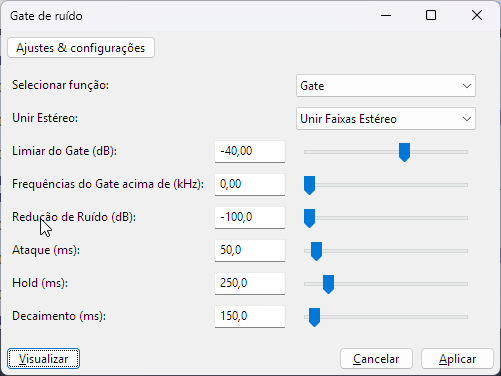
(remove as frequências baixas)
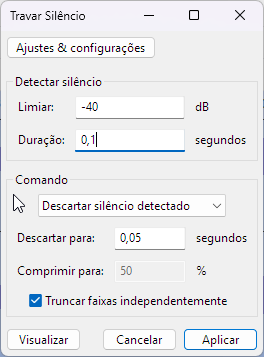
(corta as partes silênciosas do áudio e junta as pontas)
Após isso, eu recomendo que você passe o arquivo a limpo, removendo ruídos, sons de respiração, cliques, e outros detalhes menores que os efeitos e pré-processamento naõ removeram automaticamente. No treinamento de qualquer IA, dataset é tudo! Faça o seu dataset ser o melhor que puder para obter os melhores resultados. No meu caso, após revisão, eu obtive um arquivo de 7 minutos.
Aqui, uma parte selecionada do áudio original

Essa mesma parte do áudio, após o pré-processamento

Exporte o resultado do dataset como arquivo .wav em 44100hz com qualidade 32bits e vamos seguir ao treinamento do modelo:
FORK RVC DO CODENAME
Para o treinamento e inferência, utilizaremos um fork do Applio desenvolvido pelo Codename. O Applio consolidou-se como a interface padrão da comunidade por abstrair a complexidade das linhas de comando do RVC original em uma UI intuitiva. Este fork específico é valioso porque traz otimizações de backend que melhoram a estabilidade do treinamento e oferecem um controle mais granular sobre os hiperparâmetros, permitindo extrair maior fidelidade mesmo de datasets reduzidos.
https://github.com/codename0og/codename-rvc-fork-4
Após clonar, tem um script na raíz do repositório que faz a instalação do Miniconda3, junto com os pacotes necessários, pra criar um ambiente isolado pra rodar o Fork
CONFIGURAÇÕES DO TREINAMENTO
Rode a interface web na sua máquina usando o script ./run-fork.sh, e abra a interface na porta 7897 em seu navegador de preferência, aqui vamos a aba de Training:
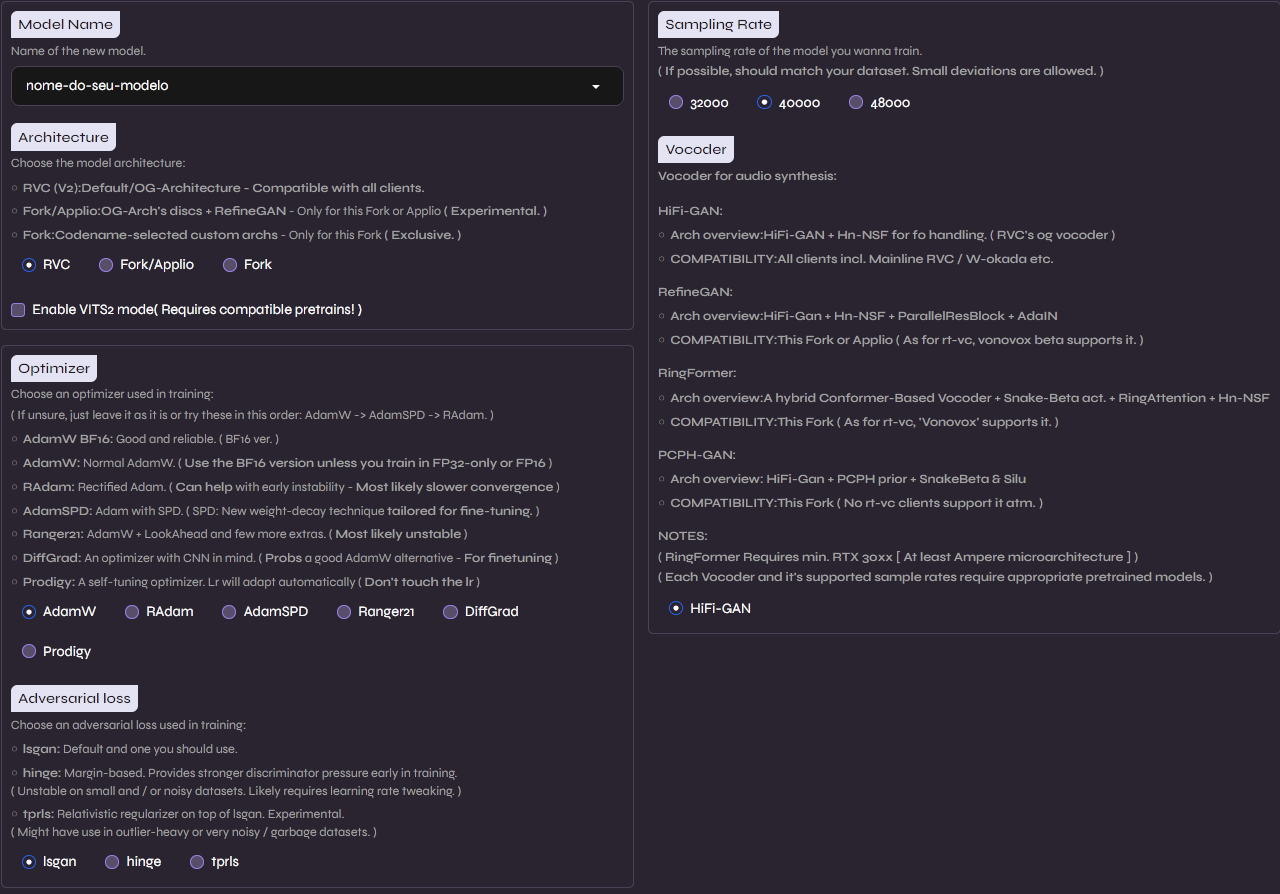
Vamos usar as configurações padrões da arquitetura RVC original, visto que essa é a mais testada e estável, certifique-se de configurar a taxa de amostragem na direita para que seja compatível com o seu dataset, variações pequenas de 2-4 KHz são permitidas, no nosso caso, com um dataset de 44.1Khz, vamos usar o modelo de 40Khz
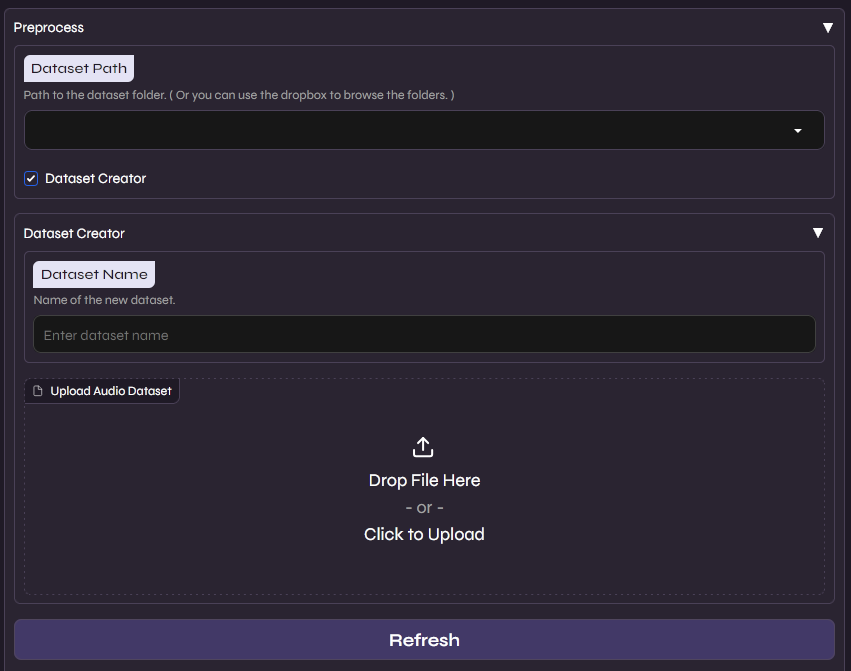 Aqui você habilita a opção “Dataset Creator” e arraste o arquivo de áudio final do seu dataset, podendo então nomear ele e fazer o upload para a interface
Aqui você habilita a opção “Dataset Creator” e arraste o arquivo de áudio final do seu dataset, podendo então nomear ele e fazer o upload para a interface
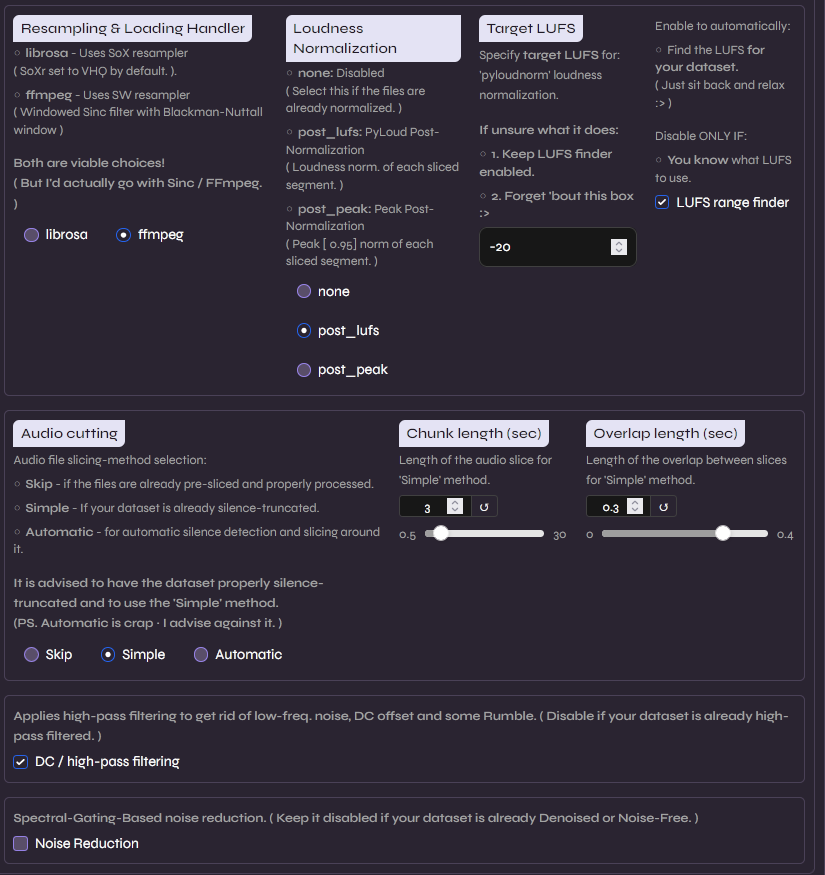 Nesta etapa, realizamos a padronização técnica das amostras. Utilizamos a normalização PyLoud com alvo de -20 LUFS para garantir que todo o dataset tenha um volume uniforme; isso evita que o modelo confunda variações de ganho com características do timbre da voz.
Nesta etapa, realizamos a padronização técnica das amostras. Utilizamos a normalização PyLoud com alvo de -20 LUFS para garantir que todo o dataset tenha um volume uniforme; isso evita que o modelo confunda variações de ganho com características do timbre da voz.
O uso do modo Simple em audio cutting é ideal aqui, pois como já tratamos os silêncios manualmente no Audacity, não precisamos que o algoritmo tente detectar pausas complexas. Por fim, o High-pass filtering é essencial para remover o “rumble” (frequências infra-sônicas) e o DC offset, que são ruídos imperceptíveis ao ouvido humano, mas que podem introduzir instabilidade no treinamento do modelo.
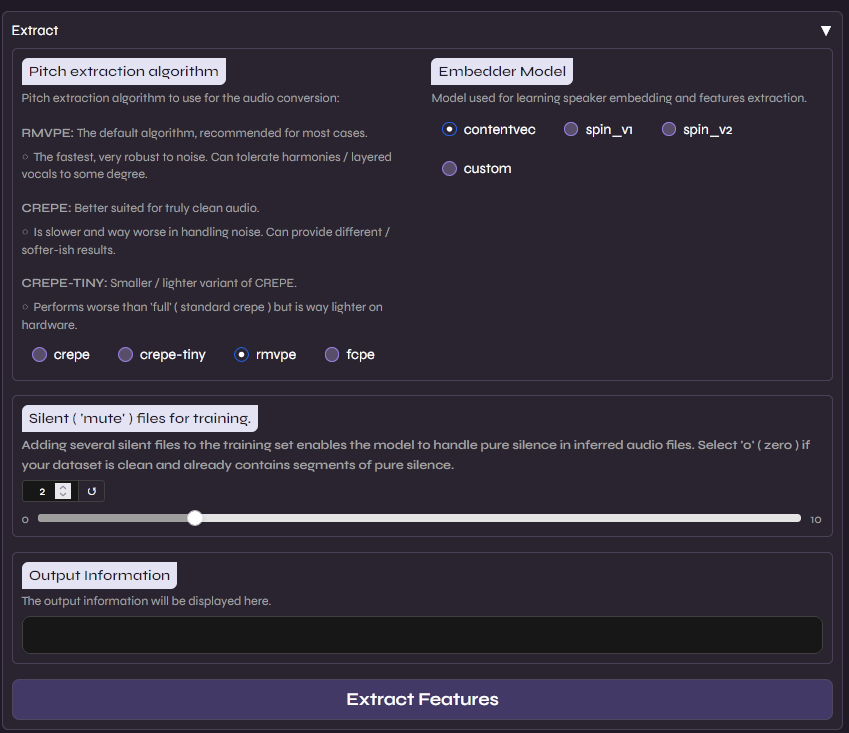 Aqui configuramos os motores de análise do áudio. Vamos utilizar os padrões, pois são os mais estáveis e bem testados
Aqui configuramos os motores de análise do áudio. Vamos utilizar os padrões, pois são os mais estáveis e bem testados
- RMVPE (Robust Minimum Variance Phase Estimation): É o algoritmo de extração de tom (F0) mais avançado atualmente. Ele é superior a métodos antigos (como Harvest ou Crepe) porque oferece uma precisão altíssima na detecção da frequência da voz, mesmo em áudios com pouco volume ou ruído residual, evitando que a voz “quebre” ou soe robótica em notas mais altas.
- ContentVec: Este é o embedder responsável por entender “o que” está sendo dito. Ele é uma evolução do HuBERT, treinado especificamente para desvincular o conteúdo da fala do timbre do locutor. Isso permite que o modelo foque puramente na estrutura fonética, facilitando a substituição do timbre original pelo timbre alvo sem “contaminar” o resultado.
Também configuramos a adição de 2 segundos de silêncio para garantir que o modelo aprenda a lidar com pausas naturais na fala sem gerar ruídos de preenchimento.
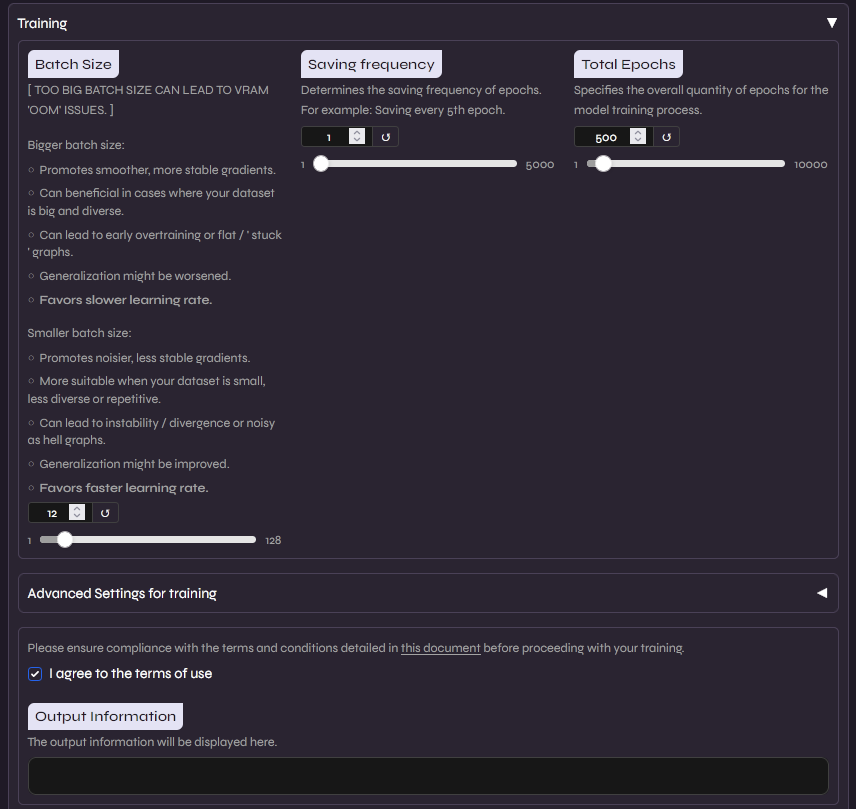 Aqui é configurado e realizado o treinamento. Para evitar overtraining, utilizaremos o Tensorboard para monitorar a saúde do modelo. Para um dataset de ~10 minutos, recomendo 200 epochs, salvando checkpoints a cada 50.
Aqui é configurado e realizado o treinamento. Para evitar overtraining, utilizaremos o Tensorboard para monitorar a saúde do modelo. Para um dataset de ~10 minutos, recomendo 200 epochs, salvando checkpoints a cada 50.
O ajuste do Batch Size é o que define se o treinamento será bem-sucedido ou se resultará em um erro de Out of Memory (OOM). Ele representa a quantidade de amostras processadas simultaneamente pela GPU. Um valor maior acelera o treino e estabiliza os gradientes, mas exige mais memória. Como regra geral:
- 8GB VRAM: Batch Size entre 10 e 14.
- 12GB VRAM: Batch Size entre 20 e 24.
- 24GB VRAM (RTX 3090/4090): Batch Size 40+.
Se o treinamento fechar sozinho ou apresentar erro de memória, reduza o valor. Se a GPU estiver operando com folga, você pode subir o valor gradativamente para ganhar performance.
Após você realizar todas as configurações, ⚠️⚠️ LEIA OS TERMOS DE USO DO APPLIO/FORK ⚠️⚠️, marque a caixinha que afirma a sua leitura dos mesmos, e clique em começar treinamento
Os modelos em treinamento pelo fork são salvos na pasta logs/, lá você também vai encontrar um script para abrir o Tensorboard, que é uma ferramenta web de monitoramento e plotagem de dados de treinamento de modelos Pytorch, certifique-se de que você tem o tensorboard e tensorflow[cuda] instalados no seu sistema.
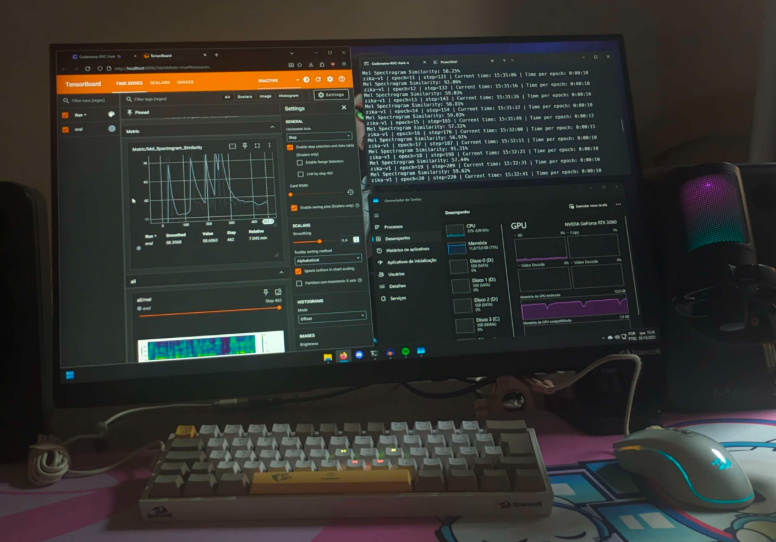
Dentro do tensorboard, vamos monitorar e verificar alguns gráficos que indicam a qualidade e fases do treinamento:
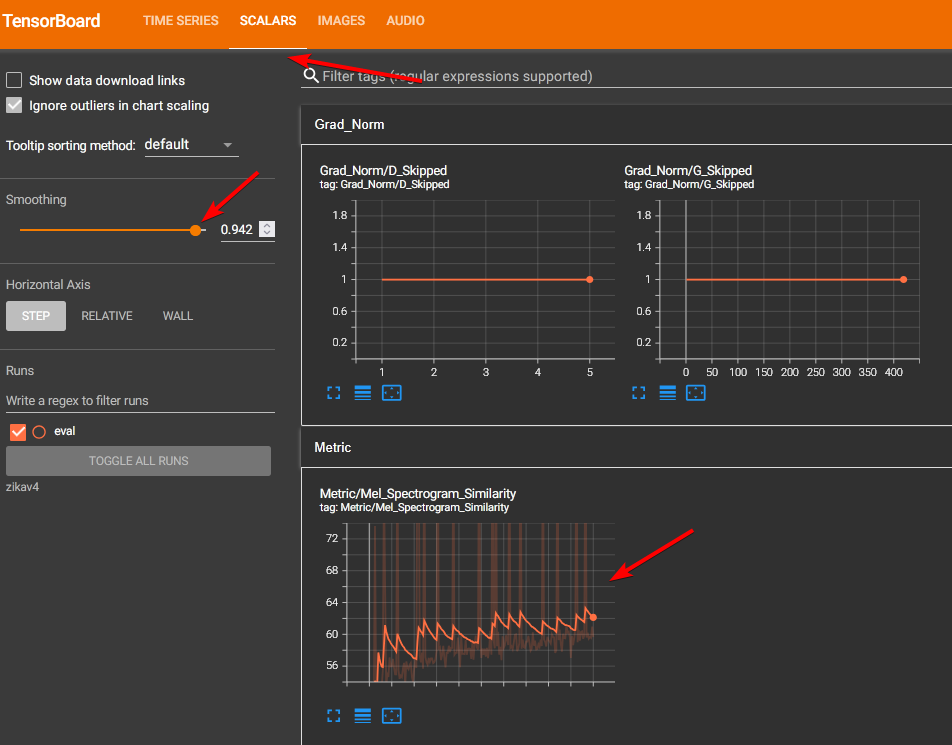
A similaridade de espectrograma Mel é uma métrica que avalia a fidelidade entre o áudio gerado pelo modelo e o áudio real do dataset, utilizando uma escala de frequência (Mel) que mimetiza a percepção auditiva humana. Em modelos como o RVC, essa métrica é essencial porque foca nas características que definem a identidade e o timbre da voz, em vez de apenas comparar ondas sonoras brutas. O objetivo é que esse valor suba gradativamente durante o treinamento, pois isso indica que a rede neural está convergindo e aprendendo a reconstruir com precisão as nuances, texturas e harmônicos da voz alvo. Por isso, esse valor deve subir gradativamente até o mais próximo possível de 100% conforme o treinamento avança
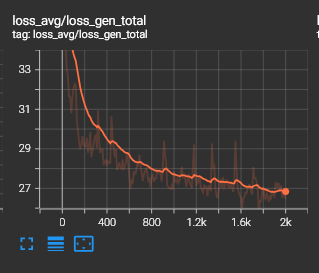
Ainda dentro da aba Scalars no Tensorboard, temos o gráfico de perda total (Total Loss) que representa a soma de todos os erros cometidos pelo modelo durante o processo de aprendizado, consolidando métricas como a perda do gerador, do discriminador e de reconstrução de feições. Diferente da similaridade Mel, este valor deve decair gradativamente ao longo do tempo. Uma curva descendente e suave é o sinal de um treinamento saudável e estável; se o valor estagnar muito cedo ou começar a subir (divergir), isso pode indicar que a taxa de aprendizado está muito alta ou que o dataset possui ruídos que estão confundindo o modelo.
Para identificar o overfitting visualmente, observe se a curva de perda começa a “subir” após um longo período de queda ou se ela começa a apresentar oscilações muito agressivas (jitter). Se a similaridade Mel estiver estagnada em um valor muito alto enquanto a perda total sobe, o modelo parou de aprender as características gerais da voz e começou a “decorar” ruídos de fundo ou imperfeições específicas do áudio. Na prática, um modelo com overfitting resultará em uma voz que soa metálica, robótica ou com artefatos sonoros estranhos.
Após o seu modelo finalizar o treinamento, clique no botão marcado para gerar o arquivo de índice, que é como se fosse um “guia” adicional de timbre e tonalidade para o modelo, e após isso podemos seguir com a
INFERÊNCIA DO MODELO
Na aba “Inference” do fork, vamos selecionar o modelo e arquivo de índice gerado na etapa de treinamento, após isso podemos seguir com algumas configurações

Para obter o melhor resultado, precisamos entender três parâmetros cruciais:
- Pitch (Transposição): Ajusta o tom da voz. Se você está convertendo uma voz masculina para uma feminina, geralmente sobe 12 semitons (uma oitava); se for o contrário, desce 12.
- Search Feature Ratio: Também conhecido como Index Rate, ele controla o quanto o modelo utiliza o arquivo de índice para recuperar o timbre original. Valores próximos a 0.75 costumam ser o sweet spot, recomendo você brincar com esse valor pois o resultado depende muito do sotaque da voz usada para o treinamento original
- Protect Voiceless Consonants: Esta configuração protege sons como “s”, “ch” e “t” de serem distorcidos pelo algoritmo de conversão de tom. Aumentar este valor ajuda a manter a clareza da fala e evita que a voz soe metálica ou excessivamente processada.
RESULTADOS FINAIS
Após 200 epochs de treinamento, obtive o seguinte resultado (lembrando que isso tudo foi feito com apenas 7 minutos utilizáveis de áudio)
Minha voz original, usada como base para o modelo converter
A saída do modelo, foi utilizado uma transposição de uma quarta abaixo do tom original, devido a voz do modelo ter um timbre menor que a minha
Como você pode ver, o modelo é muito bom em capturar o timbre e a forma como são pronunciadas as palavras, ainda é possível notar o sotaque do áudio original, o que pode ser ajustado com o valor de Search Feature Ratio mencioado antes, e também com a entonação correta do locutor do áudio original
CONSIDERAÇÕES IMPORTANTES
Os resultados obtidos com apenas sete minutos de áudio são um testemunho da eficiência do RVC. É bem impressionante como a rede neural consegue reconstruir a identidade vocal, preservando sotaques e nuances tonais com um dataset tão reduzido. Contudo, essa facilidade de acesso e execução levanta alguns pontos importantes sobre a segurança digital como deepfakes e golpes de engenharia social, ambos tópicos que eu prefiro abordar outro dia. Obrigado pela sua leitura!