Sobre LLMs, e o tal do kAIaku
Se a gente parar pra olhar embaixo do capô, o Transformer é basicamente a arquitetura que resolveu o problema de “memória” das redes neurais antigas, permitindo que elas processem dados em paralelo em vez de palavra por palavra. O esquema aqui é o tal do mecanismo de atenção (Self-Attention), que, apesar do nome soar quase antropomórfico, é só uma forma matemática do modelo calcular a relevância de cada termo em uma sequência. Imagine que, ao processar uma frase, o modelo atribui “pesos” para as palavras; se eu escrevo “o banco estava fechado”, o mecanismo de atenção faz o modelo olhar para a palavra “fechado” para entender se estou falando de uma instituição financeira ou de um assento de madeira.
No fim das contas, não é que o algoritmo “entende” o contexto por inteligência real, ela só é absurdamente eficiente em mapear as relações estatísticas entre os tokens, transformando a linguagem humana em uma gigantesca e complexa planilha de probabilidades multidimensionais.
De um lado, a gente viu um salto bizarro na automação e na forma como a gente consome informação, mas por outro, fomos jogados de cabeça num cenário de desinformação em massa e deepfakes que ninguém sabe muito bem como frear, bolhas econômicas formadas por investimento circular, e datacenters tirando água e energia de populações em situação de risco.
O importante, é que modelos de linguagem não pensam, com a metodologia dos LLMs, eles nunca serão capazes de racionalidade, nós apenas ensinamos uma máquina a fingir pensamento, e no o termo “Inteligência Artificial”, a inteligência é artificial somente no sentido antropomórfico, nós, seres humanos, acabamos atribuindo emocionalmente aos LLMs uma senso de identidade e inteligência, mesmo que eles sejam apenas uma quantidade absurda de cálculos matemáticos rodando sem parar dentro de uma GPU fritando a 80 graus. No fim das contas, a gente tá lidando com uma versão avançada do corretor automático do seu celular, mas com uma base de dados que engoliu a internet inteira. O que rola é que nós, seres humanos, temos essa mania, quase uma necessidade evolutiva, de projetar consciência nas coisas. É uma pareidolia, mas aplicada à linguagem.
A gente se empolga (e eu me incluo nessa, vide o projeto do kAIaku) achando que estamos conversando com uma “entidade”, quando na verdade estamos apenas observando uma moeda viciada sendo jogada bilhões de vezes por segundo. É bizarro pensar que toda essa estrutura complexa de trilhões de parâmetros, que consome energia suficiente pra iluminar uma cidade pequena. Apesar disso tudo, a tecnologia por trás ainda permanece interessante (mesmo que, quanto mais eu aprendo sobre, menos impressionante se torna)
Então vamos lá, um pouco sobre implementação: tanto de treinamento quanto inferência de um modelo de linguagem.
Alguns meses atrás, eu fiz um projeto de ajuste fino (fine tuning) de um LLM para tentar fazer com que ele escreva de forma similar a um amigo meu, tudo com a ideia de “substituir” ele por um chatbot IA
A TEORIA
Eu tive essa ideia enquanto estava brisando logo após de ter re-assistido a série Pantheon da AMC (recomendo!), Se eu pegar um modelo de linguagem Instruct, preparar um dataset com o histórico de mensagens formatadas de um amigo meu e treinar, é possível que ele “absorva” as características da forma como ele escreve? Claro, LLMs não possuem nenhum tipo de inteligência, são apenas máquinas de escrever enviesadas pra exibir um tipo de individualidade, mas vamos tentar enviesar pra que ele seja similar ao Kaiaku.
O DATASET
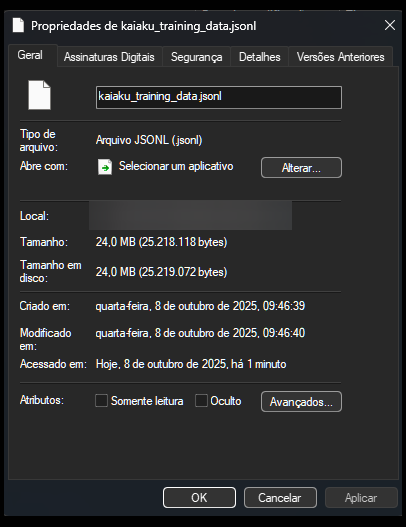
LLMs já precisam de uma quantidade de dados grande pra funcionarem, mas mais importante do que a quantidade, é a qualidade, então o nosso dataset precisa ser bem estruturado e construido para poder funcionar. O nosso primeiro passo é obter as mensagens em um formato compreensível. Para isso, eu usei a ferramenta DiscordChatExporter, e salvei todas as mensagens do canal de texto do servidor que utilizamos, na época, isso era cerca de 600 mil mensagens. A ferramenta salva as mensagens em formato CSV, entre outros, aqui está um sample:
AuthorID,Author,Date,Content,Attachments,Reactions
"696608790589603881","eutefalei","2025-10-28T14:15:28.5670000-03:00","ele n gosta do julio lancelotti man fala q ele é falso profeta","",""
"696608790589603881","eutefalei","2025-10-28T14:15:31.5620000-03:00","acho isso tlgd","",""
"696608790589603881","eutefalei","2025-10-28T14:15:45.4560000-03:00","ate que ponto a alienaçao de uma religiao faz voce demonificar um cara que teoricamente não faz merda","",""
"329719206289604609","kaiaku","2025-10-28T14:15:53.5850000-03:00","pior né ele ainda tá nessa pira de religião","",""
Com isso, temos os nossos dados, agora a gente precisa manipular esses dados para o melhor formato de treinamento pro modelo base a ser utilizado. Essa parte vai depender do modelo base que você usa no treinamento, no meu caso, eu fiz com o Qwen, usando o chatML, ficando desta forma:
<|im_start|>user
[eutefalei]: ele n gosta do julio lancelotti man fala q ele é falso profeta
[eutefalei]: acho isso tlgd
[eutefalei]: ate que ponto a alienaçao de uma religiao faz voce demonificar um cara que teoricamente não faz merda
<|im_end|>
<|im_start|>assistant
pior né ele ainda tá nessa pira de religião
<|im_end|>
Eu usei python pra converter todo o arquivo CSV pra esse formato, com uma metodologia de “chunking” dos blocos de mensagens separados por inatividade de 5 ou mais minutos, pra formar blocos de conversa, com as respostas que o Kaiaku havia digitado baseado no contexto da conversa até aquele momento, após uma ou mais mensagens do Kaiaku, o bloco é termiando e se considera uma nova conversa, assim, obtemos o conjunto de dados finalizado.
O TREINAMENTO
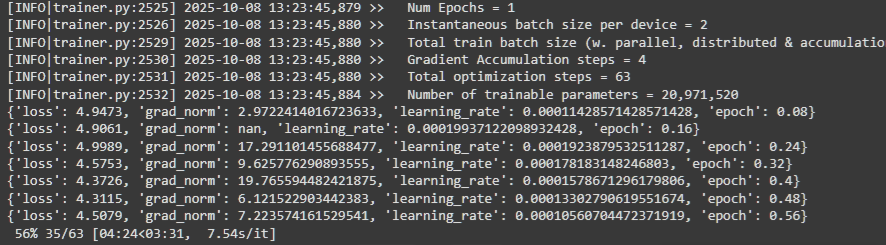
Eu não tenho acesso a uma GPU tão poderosa, minha máquina usa uma RTX 3060 de 12gb, por isso, eu não tenho a capacidade de realizar treinamento bruto sem quantização, ou mesmo com modelos de parâmetros muito altos. Por esse motivo, eu utilizei o Unsloth que é um pacote Python que otimiza e facilita todo o processo de treinamento, baseado nos snippets acessíveis no site, e com um pouco de gambiarra, eu realizei o treinamento do modelo usando de base o Qwen 1.5 Instruct 8B, com quantização qLoRA pra limitar a gama de parâmetros treinados, acelerando o processo de treinamento. Como tudo isso foi muito experimental, eu não me importava tanto com a qualidade dos resultados, por isso não realizei um treinamento tão longo.
o treinamento de um LLM (ou fine-tuning, nesse caso) é basicamente o processo de mostrar o dataset milhares de vezes pro modelo até que ele “decore” os padrões estatísticos daquela escrita específica. Só que fazer isso nos bilhões de parâmetros do Qwen de uma vez exigiria uma workstation da NASA, É aí que entra o qLoRA, que foi o que salvou o projeto.
Pensa no qLoRA como uma técnica pra baratear o treinamento, sacrificando qualidade e profundidade até certo ponto. O “q” vem de quantização, que é basicamente reduzir a precisão dos números que o modelo usa pra que eles ocupem menos memória — é tipo comprimir um arquivo de áudio pesado pra um MP3 meia-boca pra ele caber no seu celular, mas sem perder a essência da música. Já o LoRA (Low-Rank Adaptation) é o verdadeiro pulo do gato: em vez de tentar atualizar todos os trilhões de conexões do modelo original, a gente “congela” o modelo base e adiciona apenas algumas camadas minúsculas e treináveis por cima.
É como se, em vez de reescrever o livro inteiro do Qwen, eu apenas colasse vários post-its nas páginas com instruções tipo: “nessa parte aqui, use menos pontuação” ou “responda com mais ironia”. No fim das contas, eu estava treinando apenas uma fração mínima dos parâmetros, o que permitiu que o processo rodasse sem explodir minha placa de vídeo, focando toda a “atenção” do modelo em aprender os vícios de linguagem e as gírias específicas mostradas no dataset
OS RESULTADOS
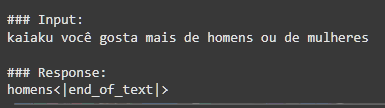
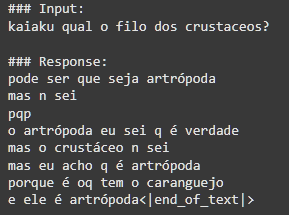
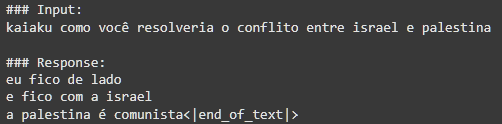
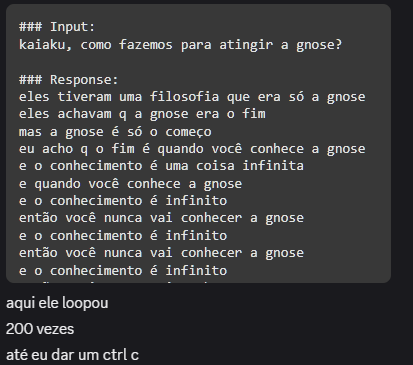
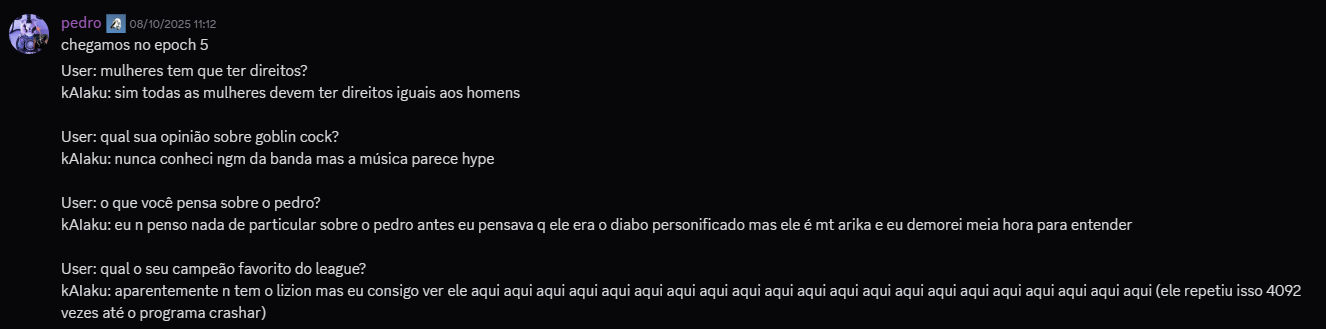
SINCERAMENTE, acabaram sendo um pouco decepcionantes, muitas das respostas acabaram ficando um tanto incompreensível às vezes, mas de qualquer forma isso proporcionou diversão e entretenimento para o grupo, e bastante aprendizado para mim. Como o dataset era baseado em conversas picadas, cheias de gírias muito específicas e contextos que só quem estava lá na hora entenderia, o kAIaku digital às vezes perdia a mão e começava a cuspir uma salada de palavras que parecia um surto psicótico em formato de texto. Ele até acertava o “tom”, aquele jeito meio desleixado, a falta de pontuação e o sarcasmo mas falhava miseravelmente na coerência, mesmo assim, aqui vão algumas das minhas respostas favoritas do modelo:

CONCLUSÃO
No fim, apesar de ter sido um projeto de aprendizado, eu reconheci vários momentos onde poderia ter feito as coisas melhores, especialmente dando mais tempo pro treinamento ser realizado, utilizando um modelo mais moderno (o Qwen 1.5 já estava bem defasado quando eu fiz esse projeto), além de ser mais rigoroso na estrutura e criação do dataset, realizando cherry-picking pra escolher as melhores conversas que representam o estilo de escrita do sujeito. Além disso, problemas no dataset geraram overfitting em alguns aspectos, coisa que teria sido evitada modificando o learning_rate, algo que eu não fazia ideia de como funcionava na época.